
I’m working through Lesson 2 of the marvelous “Practical Deep Learning for Coders” course by Jeremy Howard and Rachel Thomas of fast.ai, and last week, I trained a deep learning model to classify images of pregnancy tests whose results were not distinctly positive or negative, but were either faintly positive or showing evaporation lines. The model’s accuracy wasn’t what I wanted it to be, however, so I decided to start again with a classification problem for which I could easily acquire better sets of images than I could for the tricky pregnancy test classification problem. I then tried to train a model to classify redwood vs. sequoia trees, but again achieved a very low accuracy rate, with most of the errors coming from sequoias classified as redwoods. Sequoias’ trunks are much larger than redwoods’, but in images, it can be challenging to get a sense of scale, and I think that issue is most likely the reason why the model mistook sequoias for redwoods.
So once again, I need a new problem. I consider classifying paintings as having been painted by either Monet or Manet, but I find my own ability to distinguish between the two insufficient to check the model’s accuracy, so I decide to try Picasso vs. Monet instead. I want to be able to compare my model’s accuracy to another’s, and don’t find a deep learning model for this problem, but do find a study that trained several sets of pigeons to identify paintings by Picasso vs. Monet with over 90% accuracy! I figure beating the pigeons is an acceptable first benchmark for my model.
Following the instructions in the Lesson 2 lecture, I search for “picasso paintings” and “monet paintings” on Google Images and download both sets of images (see my previous post for the slight tweaks I needed to make to the code for this in the notebook).
On its first time out of the gate, my model beats the pigeons!

My training set loss is 0.396 while my validation set loss is 0.086 and my error rate is 0.278. It’ll be hard to improve on that! My spidey sense is pinging, though, because my training set loss is higher than that of my validation set, and I think Jeremy said in the lecture that that’s a sign of overfitting. I search and find this post on the fast.ai forum in which Jeremy says that as long as the error rate is low, a little overfitting is acceptable. Whew!
Now for some hyperparameter tuning, though the accuracy is so high that I’m not at all sure I can increase it significantly. I run the learning rate finder and try to plot the graph, but it shows as blank. There’s a tip in the notebook that says if the learning rate finder plot is blank, to try running learn.lr_find(start_lr=1e-5, end_lr=1e-1 .
That works! Here’s the graph.
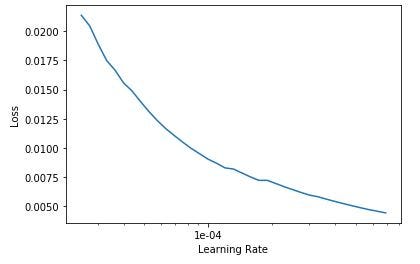
Based on the graph, I set the learning rate to stay between 1e-6 to 1e-4:
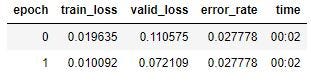
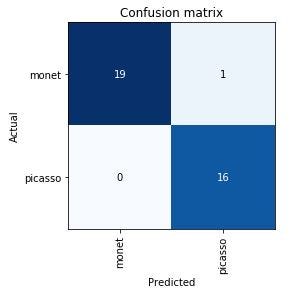
I’ve brought down both my training set loss and my validation set loss considerably, but the error rate is essentially the same (which I expected). The model only made one mistake, classifying a Picasso as a Monet.
I run the ImageCleaner, but I don’t find any poor quality or noisy images, so I keep them all. Since my loss and my error rate are both low, I think my model’s all set!
Next, I’m meant to put my model into production in a web app. I’ve played with HTML and CSS before, and like the card-carrying Millennial that I am, I absolutely did have a Geocities site long ago, but I’ve never built a web app. Jeremy says “Build a web app,” like I might say “Make some coffee,” so perhaps it’ll be relatively easy?
I follow the fast.ai instructions for deploying on Render and fork the repo provided. I run into a small roadblock: the instructions tell us to edit the server.py file in the “app” directory, but I can’t find one anywhere in the Jupyter directory tree. Eventually, I realize the “app” directory is in the forked repo on GitHub, not in Jupyter! Maybe that would have been obvious to some, but it wasn’t to me. The next tiny snag is that a variable we need to edit in the server.py file is called ‘export_file_url,’ not ‘model_file_url,’ as indicated in the instructions. No big deal.
I continue following the deployment instructions, but my web app fails to deploy, and I get this error in my logs on Render: TypeError: __call__() missing 2 required positional arguments: 'receive' and 'send' . I have no idea what that means, so I consult the fast.ai forums and find a thread addressing this issue. Apparently there’s a file called requirements.txt in the forked repo which needs the version numbers of the various libraries my model is running. I find my requirements.txt file, create a new cell in the notebook, and in it run! pip list . I find most of the values sought by the requirements.txt file, but there’s no entry for starlette, aiofiles, or aiohttp. I copy and paste the values given in the most recent post on the thread, crossing my fingers, but that doesn’t work.
So I post to the incredibly friendly and helpful forums myself and get some new values to try in my requirements.txt file.
Progress! My web app deploys, but it seems to have defaulted to the teddy bear classifier example that’s given as the default in the repo. I did update the URL link in the server.py file, but since my export.pkl was under 100 MB, I didn’t generate an API key the first time. Perhaps I need one, though, so this time I follow these instructions to do that. I edit the server.py file again with the new link, and re-deploy. Nope, still bears.
There’s an example link still in server.py, but it appears to be commented out. I’ll try deleting it? But I also edited the classes to be “picasso” and “monet” instead of types of bears, so those should have changed, too. Hmm… what if they did? Maybe it looks like the bear classifier, but it’s actually my painting classifier?
I take the advice of the Helpful Worm, and try ̶ w̶a̶l̶k̶i̶n̶g̶ ̶t̶h̶r̶o̶u̶g̶h̶ ̶i̶t̶ running it anyway.
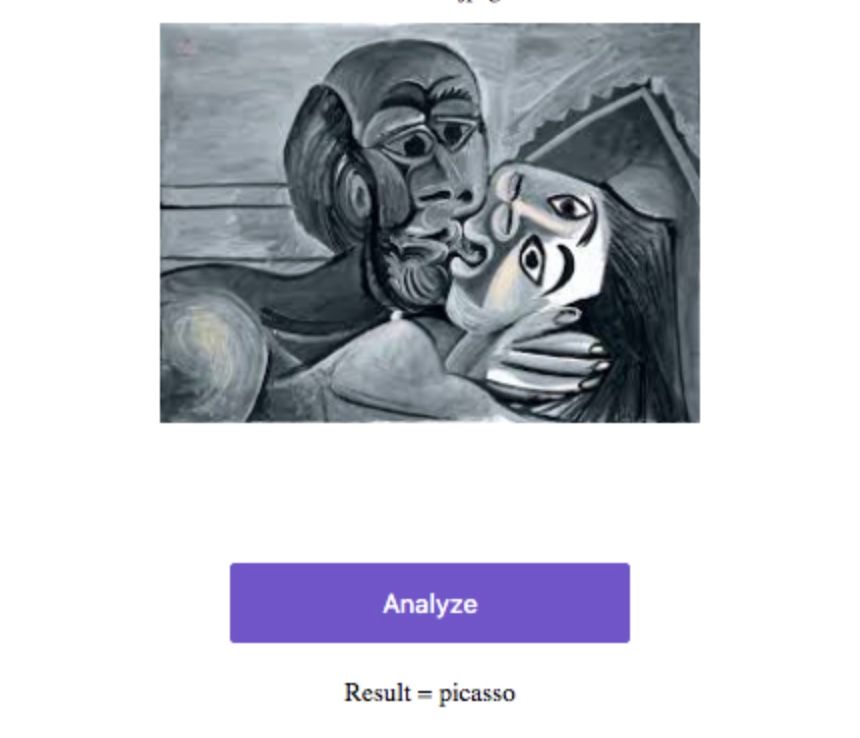
Yes! I run a Picasso image through the classifier, and the model classifies it correctly. So it is displaying as if it’s the bear classifier, while actually running my classifier.

I see that I need to edit some code for the user-facing text somewhere, but can’t figure out where to do that. The wonderfully helpful mrfabulous1 on the fast.ai forums comes through for me again and tells me that the code I need to edit is the index.html file in the “view” subdirectory of the “app” directory. It works!
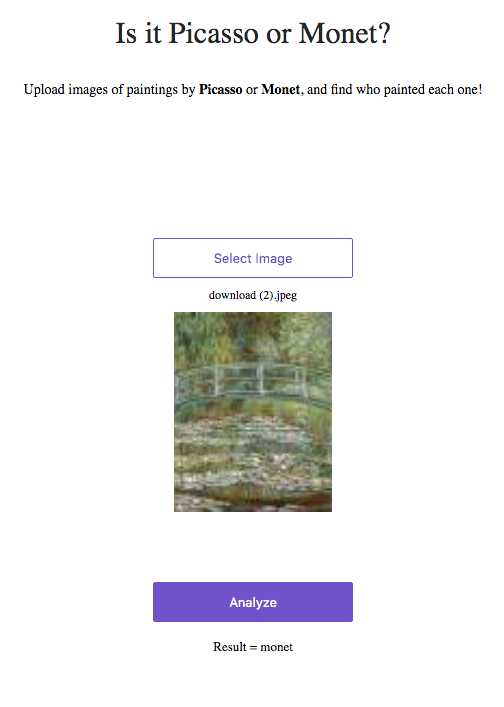
So now I have an image classification model with 97% accuracy, and a web app deployed to play with it. On to Lesson 3!
Check out the code on GitHub!
Other posts on this topic:
Lesson 1: Getting Started with fast.ai
Lesson 2 (attempt 1): Classifying Pregnancy Test Results!
Lesson 3: 10,000 Ways that Won’t Work
Lesson 4: Predicting a Waiter’s Tips
Lesson 5: But Where Does the Pickle Go?
Lesson 6: Everybody Wants to be a Cat
I’m a mathematics lecturer at CSU East Bay, and an aspiring data scientist. Connect with me on LinkedIn, or say hi on Twitter.